Attribute Release: The key to patron privacy in an era of Single Sign-On
Although attribute release may not be a phrase you’re familiar with, it’s a critical part of the infrastructure that enables organizations to protect the privacy of their users, whether that’s library patrons, educators, or researchers. It’s probably also a process you already manage in your personal life!
Every time we use a Single Sign-On solution like Google or Facebook to access an app on our phones, we’re allowing them to share some information about us with that application. Think of those annoying (but important) pop-up windows that ask us to agree to share information with third parties. In some cases, it’s just your name and email, and in others it may be more information such as access to your documents or contact list.
Attributes are simply information about you that your identity solution is sharing with a third party as part of an authentication process. Attribute release is the process by which this information is shared.
So, how does this play out when we use Single Sign-On to access educational resources that rely on our organizational affiliation? For example, a student accessing a library resource; a researcher searching for a journal article; or an academic collaborating with colleagues to write a paper.
And, more importantly, how can organizations protect our privacy when sharing the information needed to give us access to these external resources?
If you work with electronic resources - whether as an information provider (e.g. publisher) or as an information consumer (e.g. library) - here’s an overview of what you need to know about Single Sign-On and user privacy.
First, some basics
In an educational context, Single Sign-On involves 3 parties. There’s you, the user, who wants to access an online resource. There’s the service provider who provides that resource, such as a publisher or a research collaboration. And there’s the identity provider who authenticates your identity as someone with the right to access that resources i.e. your organization.
When you use Single Sign-On to access a resource, the service provider asks your organization to confirm your right to access that resource. In turn, your organization may ask you to enter credentials, such as a username and password. Once you’ve successfully authenticated, your organization will confirm back to the service provider that you’re authorized for access. And, at this point, will release one or more attributes to them.
So, what attributes are we talking about?
Attributes come in several different flavors, depending on how much information the service provider needs in order to successfully deliver service:

Why do we need attributes at all?
Attributes are important because they give organizations and their service providers greater control over your experience. For example:
- Access control: a resource could be limited to users who are full-time staff, preventing, say, alumni or contractors from access
- Cost control: a resource could be limited to users with a certain role or from a certain department
- Risk control: pseudonymous identifiers allow users to benefit from personalization without the risks associated with sharing and storing personal credentials with yet another service (and the hassle of remembering yet another username & password).
What’s recommended practice here?
NISO is a member of The Coalition for Seamless Access, an important cross-industry initiative aimed at simplifying institutional access to online resources via Single Sign-On. They recommend the following practices for attribute release:
- By default, organizations should only share anonymous or, if necessary, pseudonymous attributes with service providers.
- Service providers should only request the least-intrusive set of attributes needed and shouldn’t retain any extra attributes received. If more information is desired from users, consent must be sought and users should have the opportunity to add/review/edit the information they share e.g. via a profile page.
- Attributes shouldn’t be used by service providers for non-access purposes without prior consent or proper legal basis, and should be deleted or anonymized when no longer needed for service access.
And what does that mean in practice?
Attribute release needs to vary according to the differing needs of service providers. For example, here are 4 different real-world scenarios and the attributes needed to support them:
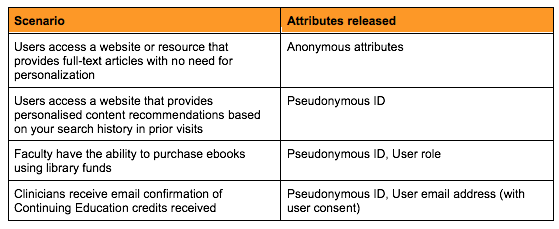
Getting this right requires coordination within organizations to ensure that the attributes released by internal identity systems (typically controlled by IT) reflect the needs of the users and the services they want to access (typically managed by other departments, such as the library). These conversations need to start with a common understanding of the critical role that attribute release plays in resource access.
Can we make this coordination easier?
Yes! We all face a similar challenge in managing how we share information via social networks - it’s much easier to arrange your contacts into groups (friends, family, work etc) and to set rules on sharing at the group level, rather than manually configuring them for each person.
The Coalition for Seamless Access is similarly exploring how service providers could be grouped into categories based on their attribute requirements. This would allow organizations to automate attribute release based on a service provider’s category, rather than having to manually configure attributes for each service provider.
For example, the attributes needed to enable access to library resources are typically far more limited that those needed to support research collaboration between academics in different institutions.
Interested in learning more?
If you’d like to learn more about The Coalition for Seamless Access, or would you like to get involved in the development of standards in this area, please visit https://seamlessaccess.org/.
