Introduction
Cartography of NISO Plus 2021

The second NISO Plus Conference was held virtually on February 22-25, 2021. This year’s theme was “Global conversations — global connections.” The event brought together 850 participants from 26 countries, with a high level of engagement during the 52 sessions. As it was in the previous year, NISO Plus is a “sage not on stage” event, which translated into many interesting discussions across the live Q&As, Twitter, and the NISO Community Forum.
Another element that made the NISO Plus 2021 program unique was the effort to enable networking moments to get more conversations started. Jeopardy NISO Edition was an interesting way of learning and thinking about standards, and the session included more than 80 participants. “We were thrilled to have so many attendees engaging and learning about NISO standards, events, and community activities,” commented session host Raymond Pun, of the Hoover Institution.
In recognition of their commitment to improve diversity, equity, and inclusion in the information community, 15 professionals were awarded NISO Plus 2021 Scholarships, with the support of Digital Science. This is the second year these scholarships were awarded.
In the next sections, we will recap the most important takeaways of the event, from our perspective. (Note: the authors were both NISO Plus 2020 Scholarship awardees and part of the NISO Plus Planning Committee).
Diversity, Equity, and Inclusion (DEI) and Accessibility
Diversity, equity, and inclusion (DEI) and accessibility were central themes of NISO Plus 2021. Many sessions focused on ongoing efforts to improve DEI and accessibility across the information community.
During the session A Focus on Accessibility, Mike Capara (The Viscardi Center) raised the need for a clearer understanding of digital accessibility. An important point was made by Solange Santos (SciELO): Improving accessibility in digital libraries improves the user experience for all, not only for people with disabilities. Accessibility starts at the top of the organization and necessarily requires a cultural change. Speakers encouraged the community to start improving accessibility as soon as possible for community benefit, as well as in light of many national and international regulations in place [1]. The EU Accessibility Act takes effect in 2025, at which time all digital content must be accessible to people with disabilities, by law [2].
Data aggregators are in a unique position to influence accessibility awareness and implementation among content creators. SciELO is working in this direction.
In the session Standards That Support Diversity, Equity, and Inclusion, Trevor Dawes shared what the library at the University of Delaware is doing in order to be truly inclusive, such as making sure there’s relevant material for all students/researchers and that this material is diverse (e.g., not Eurocentric, includes authors from all possible backgrounds), making sure its services are accessible and adaptable to all users, and so on.
They also have been holding internal audits in order to review hiring processes (from where the job position is posted to the questions asked in job interviews), to make sure that both users and staff feel welcome and comfortable, and to analyze if there’s equity in the organization (noting that diversity is not the same as equity).
The importance of speaking up about disabilities (and self-identification) was highlighted during the panel as being beneficial for both employers and employees, as it can help employers provide better working conditions and helps destigmatize people with disabilities.
Indigenous knowledge (IK), defined as “the understandings, skills and philosophies developed by societies with long histories of interaction with their natural surroundings,” was also a recurring theme, with Katharina Ruckstuhl (University of Otago) mentioning the importance of Indigenous Data and Sovereignty (IDS) in order to preserve IK, so that indigenous peoples own their data and can control their information, thus avoiding exploitation, appropriation, and erasure of their community knowledge. The CARE principles, developed by GIDA (Global Indigenous Data Alliance), complement the FAIR principles in an effort to recognize indigenous data sovereignty and governance.
In the keynote address, Connecting the World Through Local Indigenous Knowledge, Margaret Sraku-Lartey spoke about indigenous knowledge (IK) originating from African countries; how IK is often overlooked by current scientific knowledge and research and also needs to be recorded so that it’s discoverable for researchers; and that guidelines for this are necessary. Sraku-Lartey also focused on how intellectual property rights of indigenous peoples are often abused or ignored, as this knowledge is usually extracted from those communities and capitalized on by others, without ever recognizing them. The need for metadata for IK was raised during both sessions, and we look forward to NISO’s next steps in facilitating discussions about this.
It all relates to the African proverb that “when an old man dies, a library burns to the ground.” People are living libraries, and libraries provide infrastructure for society to access knowledge. As Ginny Hendricks of Crossref brought to the table in her session, in the end, infrastructure is about the people.
Preprints
The session Quality and Reliability of Preprints offered broad institutional views on preprints, from two servers, AfricArXiv and SciELO Preprints, and the National Institutes of Health (NIH) Preprint Pilot.
Joy Owango, Executive Director of AfricArXiv, presented an overview of that server, which was established for African researchers or individuals doing research in or about Africa. AfricArXiv adheres to the African Principles for Open Access in Scholarly Communication; it also has a program that encourages researchers to publish in local or regional languages and then helps them translate that research into English.
Owango discussed some of the reasons why research output from Africa is underrepresented in scholarly publishing: the language barrier; regional bias in western journals; a large quantity of African research that is published in print only; and infrastructure issues, like network challenges and internet connectivity.
As for the SciELO Preprints server, it’s run by SciELO using OPS (Open Preprint Systems), developed by PKP (the Public Knowledge Project). SciELO has been encouraging its journals to adopt open science practices for a few years now, and SciELO Preprints is part of this collective effort. The server started operating in April 2020 and, even though it is open to all areas of knowledge, it mostly received submissions of COVID-19-related papers. Seventy percent of submitted papers are from Brazilian authors, 20% from Latin American authors, and the remaining 10% are from other countries.
Abel Packer (SciELO) noted that preprints are adopted when there’s a sense of urgency in communicating research, and it’s important to understand that they add complexity to the management of the quality of the research but “enrich our research community infrastructure.”
Packer also stated that “preprints’ power resides in [their] web disintermediation property. So when you feel the need to publish, you have the new opportunity because you [make the] web, and its disintermediation property [allows for that].” SciELO has been saying that the future is open for the last few years, and it certainly feels true now!
The reliability of preprints was also discussed. In Misinformation and the Truth: From Fake News to Retractions to Preprints, Michelle Avissar-Whiting of Research Square showed how three preprints posted on their platform were publicly received. One was “misunderstood” (created clickbait-y claims); one was “over-interpreted” (read very literally and not comprehensively); and the last became a “convenient truth” (used to push conspiracy theories or a political agenda). Avissar-Whiting ended her talk by arguing that it’s better for flawed research to be published as a preprint and quickly discredited than to be formally published and cause harm, using the Lancet article linking autism to MMR vaccines that took 12 years to be retracted as an example.
Research Data
The sessions dedicated to FAIR, linked, and research data discussed and proposed ways data sharing and its standardization can be improved for the benefit of the community.
There was a strong focus on research data policy and how organizations across the research landscape (e.g., publishers, funders, research institutions) are working to standardize these policies. It was noted by Todd Carpenter, NISO Executive Director, that data sharing and citation is still in its very early days, so standards and frameworks created now will still be changing and evolving for a while.
Raising awareness of FAIR principles among researchers and contributors is very important, especially concerning data availability statements, FAIR repositories, and benefits. Persistent identifiers (PIDs) are a central principle (F1) of FAIR data, and hence it’s crucial to increase awareness of PIDs in data management.
To encourage best practices for data and information sharing, it’s important to give credit to those curating and depositing data, said Christian Herzog, Dimensions CEO. PIDs are important and good metadata is even more important, said Shelley Stall (AGU). Stall also raised the importance of ORCID iDs and DataCite DOIs to increase recognition for software [3], and for datasets and their creators.
SciELO launched its Data Repository (powered by Dataverse) last August, which can be used by authors who submit manuscripts to SciELO Network journals and the SciELO Preprints server. The repository follows FAIR principles.
Identifiers and Standards in Open Research Infrastructure
PID Graph
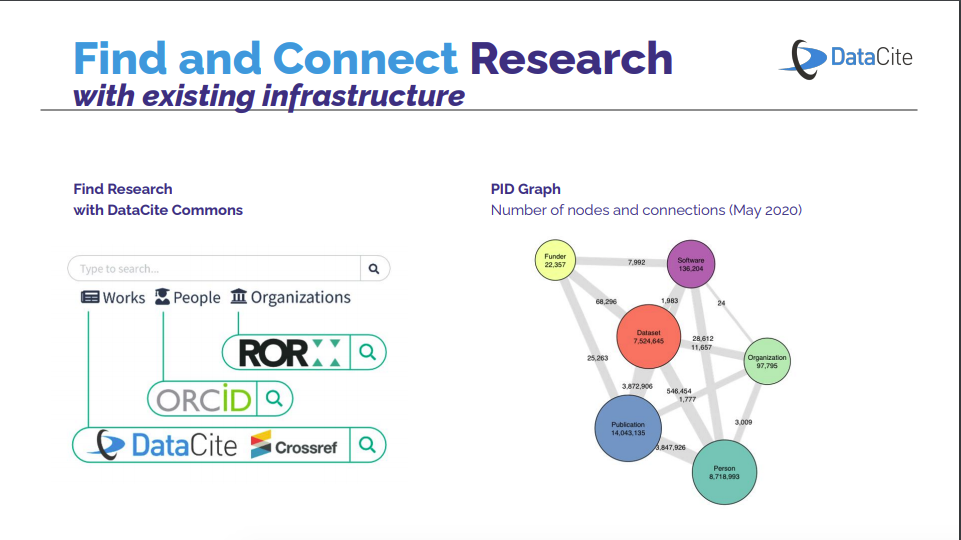
The session Identifiers, Metadata and Connections discussed how mixing persistent identifiers into metadata makes connections between research work.
In real life, researchers, contributors, organizations, and their outputs are interconnected in multiple and complex ways. Persistent identifiers for individuals (ORCID iDs), outputs (Crossref and DataCite DOIs), and organizations (ROR IDs) allow us to better understand and follow those connections. Making those connections and their information accessible to all in the form of open metadata helps effectively map the research ecosystem and increase trust and transparency in research and its infrastructure. The benefits of persistent identifiers can be increased if these are combined and connected via their metadata, illuminate the research process and activities (e.g., who contributed to a paper, who reviewed it, have any concerns been raised, who funded it, links to underlying data and code), and recognize researchers and their contributions as well as the organizations supporting them.
Open Versus Proprietary in Softwares and Systems was a roundtable panel discussion moderated by Leslie Johnston (National Archives) in which panelists discussed the advantages and disadvantages of open and proprietary softwares and systems. The main takeaway from the session was that proprietary software is better for a quick, more robust solution with good, specialized support, but that open software is more sustainable in the long term, as it is community-led and allows for more transparency and customization, even if it’s more work to keep running and updated.
In regards to software and system development, standards can be really helpful in the sense that it’s more sustainable (and easier) to work with pre-established standards than it is to code everything from “the ground up,” allowing, too, for better interoperability options. This topic was also discussed at the Standards in Open Research Infrastructure session, another a roundtable discussion, led by Natasha Simons from the Australian Research Data Commons. In that session, Daniel Bangert (Digital Repository of Ireland) mentioned that standards help with interoperability and with ensuring reliability and quality, tohelp make sure everyone “speaks the same language.” Arianna Becerril-Garcia (Redalyc) noted that open research infrastructure helps make content more openly accessible, disseminated, connected, and discoverable.
Open Infrastructure Governance
In the session Business Models of Infrastructure Support, Ginny Hendricks mentioned that Indonesian organizations account for almost 14% of Crossref’s membership, which she used to illustrate the diversity of their membership and the fact that organizations from regions beyond the global North make an important contribution to Crossref’s sustainability. Both Hendricks and Rebecca Kross (the Canadian Research Knowledge Network, or CRKN) highlighted the importance of people in open infrastructure’s sustainability: from users, staff, board members, institutional members, and advocates all play an important role in adopting and developing infrastructures.
Accountability was an important topic in the session, and it was mentioned that organizations like Crossref and ROR (Research Organization Registry) have recently committed to the Principles of Open Scholarly Infrastructure. The complex relationships between nonprofit and commercial organizations were also discussed. In this regard, CRKN’s work with for-profit organizations is driven by member-defined principles with the goal to promote sustainable scholarly communications and equity of access for all, not just in Canada, according to Kross.
Retractions
Retracted research was one topic discussed in the Misinformation and the Truth: From Fake News to Retractions to Preprints session. Caitlin Bakker from the University of Minnesota noted that there’s a problem with the potential use of retracted research without the knowledge of its retracted status (for example, a doctor might use a retracted paper to diagnose a patient); beyond that, there also isn’t consistency across platforms, and often retraction notices aren’t public, easy to find, or linked to in the original paper.
Jodi Scheider from the University of Illinois Urbana-Champaign made a few recommendations in this regard: Make retraction information easy to find and use; recommend metadata and taxonomy; create best practices for the retraction process; educate and socialize researchers; and develop standards, software and databases for sustainable data quality. NISO will organize working groups to work on retraction guidelines.
NISO Update
The NISO Update session brought us an overview of three projects currently underway: MECA (Manuscript Exchange Common Approach), the Content Platform Migrations Working Group, and KBART (Knowledge Bases And Related Tools).
MECA is a standard that “sought to agree on a methodology to package up files and metadata in order to transfer that package from one submission system to any of the others.” It became a NISO Recommended Practice in 2020 and reconvened in 2021 as an established standing committee. The MECA committee is currently working on expanding its recommendations by looking at more case studies and incorporating peer review.
The Content Platform Migrations Working Group is working to develop recommended practices in order to help normalize content platform migration processes and provide recommendations to improve communications before, during, and after migrations. Its draft is currently open for public comments (from March 10 to April 23, 2021), and any contributions made will be considered by the working group.
KBART “is a NISO Recommended Practice that facilitates the transfer of holdings metadata from content providers to knowledge base suppliers and libraries.” It is now into Phase III, which has among its goals the ability to allow more granular information, improve its usefulness for non-English/European language content, and improve and clarify its endorsement process.
Conclusion
Diversity, equity, and inclusion (DEI); accessibility; and the challenges presented by an on-going pandemic were transversal topics throughout the conference.
The NISO Plus 21 Planning Committee was a global, diverse and community effort that helped shape the conference experience. The group comprised 26 individuals representing different geographies, career stages, sectors (libraries, publishers, vendors, infrastructure providers, and more), and organizational size and structure. It is important to mention that the conference hosted sessions across all time zones, offering live discussion opportunities to all attendees. “Conference delight” was the guiding principle for event planning, and each of the platforms used for NISO Plus was carefully and deliberately selected to make it a unique and joyful experience for all.
NISO Plus continues to be an open space for discussion, and this year’s edition redoubled efforts to enable wider participation. Last year it was discussed that “open is not enough,” and that the necessity exists to “decolonize scholarly communications and think of those voices “missing in the room.” At the previous year’s conference, Carolina Tanigushi was the only person representing an organization outside the global North. At NISO Plus 2021, the participation of delegates from South America, Africa, and Asia increased, and so did the inclusion of different voices and perspectives across the community. We the authors believe that inclusivity should be a praxis, not just a slogan. If we want to solve global problems, we can’t afford to work in silos or ignore the diverse practices and needs of our community.
Topics relating to open science were already a big part of the conversation, but the pandemic has brought them into the spotlight, pushing for quick changes in the research ecosystem, especially in regards to practices that allow for faster posting and publication and for more transparency in the publication process. Suddenly, for better or worse, preprints were being talked about on the news, and reliability of and trust in science was being discussed on a much broader scale, especially considering some high-profile papers on COVID-19 that were retracted, whether they were still preprints or published in well-known journals.
Sylvain Massip of Opscidia highlighted three major challenges of science communication: discoverability, access, and trust. While we can’t control how society will receive or interpret scientific information, standards (and other open science practices) can be used to enable this interaction by making it easier for research outputs to be found, accessed, and used, to ultimately increase trust in science for all.
After its second edition, we can confirm that NISO Plus has been established as a sustainable and plural discussion space for all those interested in the information ecosystem. As part of the 2020 NISO Plus Scholarship cohort, we experience, recognize, and celebrate NISO’s leadership in fostering inclusion and participation. NISO really goes the extra mile in practicing what they preach and giving opportunities, support, and encouragement to all those interested in improving trust in information. After all, that’s why we use and need standards, to build trust in information and practice, and promote good and responsible citizenship. In that sense, it’s really important for our community to gather and find solutions that work for all. It takes a village, and a global one!

