Frequently asked questions about SUSHI, for developers
- How does the SUSHI protocol work?
- What is the relationship of the SUSHI standard (Z39.93), the SUSHI schema, and the SUSHI WSDL?
- Where can I find the SUSHI schemas and WSDL?
- How often is the SUSHI schema updated?
- What are the various technologies involved with SUSHI implementation?
- What is the difference between the client and the server implementation of SUSHI?
- What variable information has to be supplied in a SUSHI (client) request?
- What variable information has to be supplied in a SUSHI (server) response?
- If I am a content provider, what are the major basic steps involved into SUSHI implementations?
- If I am a system developer, how do I implement the client side of SUSHI?
- Are there tools to help developers get started?
Descriptions
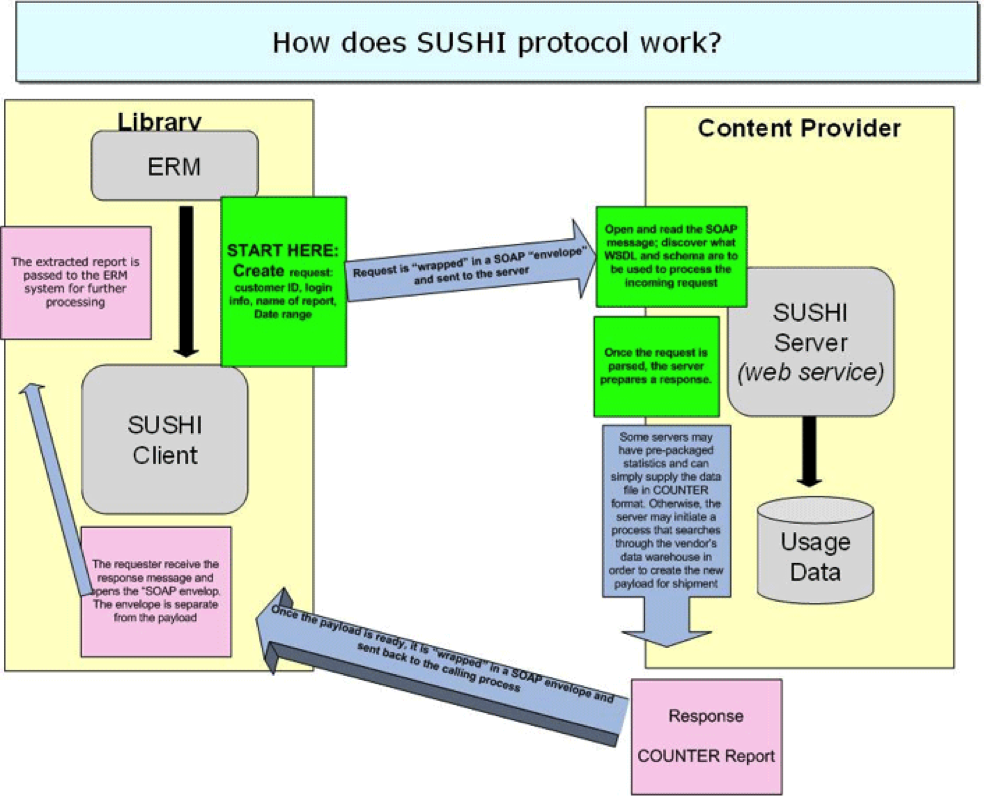
1. How does the SUSHI protocol work?
The below image shows how the protocol works.
2. What is the relationship of the SUSHI standard (Z39.93), the SUSHI schema, and the SUSHI WSDL?
The SUSHI standard is the high-level framework in which the SUSHI Schema, SUSHI WSDL, and COUNTER reports operate. The SUSHI WSDL describes, with a high level of abstraction, how the client and server sides of the web services transaction will interoperate. The WSDL gives information referring to the lower level, more detailed and specific information about the transaction, which is described in the schema. The schema is the XML code that is used to perform the SUSHI operation. Variable information in the schema is modified at the time the code is executed. The COUNTER XML report is the actual payload of the transaction.
- SUSHI standard
- SUSHI schema
- SUSHI WSDL
3. Where can I find the SUSHI schemas and WSDL?
The latest SUSHI schemas and WSDL are available at the NISO SUSHI schema webpage. Additional resources can be found on the main SUSHI website: http://www.niso.org/standards-committees/sushi.
4. How often is the SUSHI schema updated?
Changes to the schema that meet the standard's definition of allowable changes will be made as needed, but no more than annually. The protocol is intended to be robust enough to accommodate new COUNTER reports and releases without any changes to the SUSHI schema.
5. What are the various technologies involved with SUSHI implementation?
What is SUSHI protocol? The SUSHI protocol is a standard client/server web services utilizing a SOAP request/response to retrieve the XML version of the COUNTER report.
What are Web Services? Web services are server-based software applications that are accessed through a network and provide information or other responses to standard, XML-based messages. They are platform-, application-, and language-independent; services are akin to collections of software functions that can be called remotely by any application that conforms to a specified protocol. The inputs, outputs, formats, and parameters of a web service are typically defined by a WSDL and may be registered in a Universal Description, Discovery, and Integration (UDDI) directory. SOAP is a particular Web services message protocol that is a W3C Recommendation. SOAP messages are frequently, though not necessarily, used to interact with a Web service. A real-world example of a web service is Google's SOAP Search API, which a developer can use to incorporate Google search functionality into third-party software. More on Web services.
What is WSDL? WSDL (Web Service Description Language) is an XML format used to completely describe a Web service. The WSDL defines the operations or functions the service provides, the formats and parameters used to access them, the transport mechanism (e.g., SOAP) used to send and receive input and output messages, and the Web address(es) where the service is located. A complete WSDL can be used to create a functional client that can send requests to the WSDL's corresponding service and receive its responses.
What is SOAP? SOAP is an XML-based protocol used for exchanging messages between two networked computers. The communication occurs through HTTP, just like a Web browser. The SOAP specification is a Recommendation of the World Wide Web Consortium (W3C).
What is an ERM? Electronic Resource Management (ERM) software is developed for the specific purpose of managing a library’s electronic resource collections and subscriptions. An ERM system, which can be either standalone or directly tied to a library system vendor’s other modules, usually track the life cycle of an electronic resource. This can include management areas such as: access, acquisitions, licensing, cost, invoicing, workflow, trial use of electronic products, and resource usage.
Many of today’s ERM systems are based on the Digital Library Federation’s Electronic Resource Management Initiative report.
What is an XML schema? An XML schema is “is a description of a type of XML document, typically expressed in terms of constraints on the structure and content of documents of that type, above and beyond the basic syntax constraints imposed by XML itself. An XML schema provides a view of the document type at a relatively high level of abstraction”. [Source: XML schema. (2006, July 6). In Wikipedia, the Free Encyclopedia. Retrieved July 27, 2006.]
More on XML.
6. What is the difference between the client and the server implementation of SUSHI?
The SUSHI client application packages a request for a usage statistics report and sends it to a compliant SUSHI server. The SUSHI server parses the incoming request from the client, including the specific report requested and the identity of the customer for whom data is to be retrieved. A server may either have prepackaged customer’s data ready for immediate delivery or it may search its data store contemporaneously with the request and create the response ad hoc. In either case, the server returns the requested report in XML format.
7. What variable information has to be supplied in a SUSHI (client) request?
In the current release of SUSHI (ANSI/NISO Z39.93-2007), the mandatory variable information to be supplied in a SUSHI request is:
- Requestor ID: Use the identifier provided by the content provider you are requesting usage from. In some cases this might be long string of numbers and letters; in other cases the domain of the service making the request might be sufficient.
- CustomerReference ID (which may or may not be the same as the Requestor ID) and is the identifier by which the content provider knows the institution usage is being requested for.
- Name of the report being requested
- Release (i.e., version) number of the report being requested
- Begin date of the report being requested
- End date of the report being requested
There are additional variable fields that can be supplied in a report request which are recommended or optional that are not included in the list above. Refer to the standard for the complete list of available fields.
8. What variable information has to be supplied in a SUSHI (server) response?
In the current release of SUSHI (ANSI/NISO Z39.93-2007), the mandatory variable information to be supplied in a SUSHI response is:
- Requestor ID (repeated from request message)
- Report name, release, and dates (repeated from request message)
- Report (the actual XML payload with the report data)
- Exceptions (only if applicable, any exception or error messages)
9. If I am a content provider, what are the major basic steps involved into SUSHI implementations?
SUSHI's role in this environment is merely the delivery of a usage report from a content provider to a library. The most common report being delivered is COUNTER Journal Report 1; however, Database report 1 is also of interest to many.
If you review the COUNTER Code of Practice for Journals and Databases (http://www.projectcounter.org) you will see more details on the reports and the expectations for reporting. One thing you will note is that reporting of full-text downloads is the responsibility of the site actually delivering the full text. Typically a federated search engine assists users in finding and retrieving things held at other sites; therefore, they are not actually hosting the content or directly delivering it. This means that, from a technical perspective, a federated search engine would not be responsible for delivering COUNTER reports. However, this does not prevent them from providing usage reports in COUNTER format and allowing those reports to be delivered by SUSHI.
The first place to start would be in analyzing how you are capturing your usage statistics for your site. Can you produce a COUNTER report today? If not, that would be the place to start.
The next step would be to produce that COUNTER report as XML using the COUNTER schema -- we would recommend you use the latest schema that appears on the NISO website.
Once you have the ability to produce a COUNTER report, the next step would be to determine a simple security model. Your customers will most likely want to be sure that you don't allow unauthorized people to access their usage. The security model could be as simple as restricting which IP addresses are eligible to request usage for a particular customer.
Now you can produce a COUNTER report in XML format and you have a simple security system in place you can start on the SUSHI implementation.
Ideally, you will have created some kind of a service layer for your reporting services. For example, your user interface for your COUNTER reports collects the specific parameters, such as which report and what date range and customer code from the user, then passes this to your COUNTER web service that pulls the data and formats and returns the report. If you have this in place, then SUSHI becomes fairly straightforward:
- Create a SUSHI web service that captures the SUSHI request
- Analyze the request and verify the following (return errors as appropriate):
- verify that you want to allow that client to request usage (e.g., a check of their IP)
- verify that the customer code is valid
- verify that you can deliver the requested report
- verify that the date range is valid
- Call your reporting service to fetch the requested COUNTER report for the customer and date range specified
- Assemble the SUSHI Response inserting the COUNTER report or appropriate error code. Send back the response.
The above assumes you have some experience in writing web services using .NET or JAVA. If not, you may want to look for resources to help bring you up to speed on that first.
Other recommended resources:
EBSCO's SUSHI Software Development Kit (SDK) [for servers]
http://code.google.com/p/ebscosushisdk/
10. If I am a system developer, how do I implement the client side of SUSHI?
The first place to start is the Getting Started guide for developers of client applications, found below on this page. This document will help you understand and organize the work to do to create your own client. It also recommends reviewing the MISO client, which is a freely available SUSHI client that comes complete with source code (http://code.google.com/p/sushicounterclient/).
11. Are there tools to help developers get started?
Below is a summary of some tools; a longer list is available at http://www.niso.org/workrooms/sushi/tools/.
EBSCO's SUSHI Software Development Kit (SDK)
http://code.google.com/p/ebscosushisdk/
This SUSHI SDK (software development kit), from EBSCO’s developer Richard Carruthers, is now available on Google Code and is available for use under the new BSD license. The project description is: "This SDK includes .Net classes that will facilitate working with COUNTER 3.0 data and SUSHI 1.6 services. Whether the intended solution is a SUSHI client or server, these classes will provide the groundwork to allow developers to focus on the logic rather than implementing the standard."
MISO: Serials Solutions' Open-Source Code for SUSHI Client
http://code.google.com/p/sushicounterclient/
The Serials Solutions open source SUSHI client code will enable libraries to build consistent, stable, and standards-based tools. It is the first release of what the maintenance committee hopes will be many open source toolkits for libraries.
How to Start Building a SUSHI Service
http://docs.google.com/View?docid=d2dhjwd_140d923m7fh
This draft document by Tommy Barker, Software Engineer, IT & Digital Development, at the University of Pennsylvania Library, is a work in progress -- and a valuable tool for those interested in getting started with building a client. As it states in the beginning, "Before building a SUSHI client, it is a good idea to first test the service with reliable third party tools to see if it is working properly. Additionally, you will have a sample request and response to help model your client." This aims to show how.
Getting Started: For Developers of SUSHI Servers
In basic terms, The SUSHI protocol provides instructions to automate the collection of usage statistics reports, which librarians would otherwise manually download from a vendor website or receive via e-mail. SUSHI is a relatively simple request-response protocol that calls for a client-server implementation. Typically the usage statistics management software used by librarians will act as a client that sends a request to a web service on implemented by a publisher or content provider. If you are a developer working for a publisher or content provider, it is this web service that you will be developing.
Remember that as you embark on this project you are not alone. The SUSHI developer list (http://groups.niso.org/lists/sushidevelopers/) provides you with access to a number of experts who can answer questions and provide guidance.
You will find lots of helpful information on the SUSHI website that will make your job much easier. Below is a quick checklist of things you need to consider:
TaskSuggestions and Resources
You need to have access to the COUNTER compliant usage statistics for the content provider/platform that you are implementing the web service for.This is something you need to pursue with the organization you are developing the service for.
You need to determine which reports you need to support.The type of reports you need to support is dictated by COUNTER. Releases 3 and 4 of the COUNTER Code of Practice (http://www.projectcounter.org/code_practice.html) lists the reports needed for compliance in section 4. Another quick reference to the needed reports is the Compliant Vendors table on the COUNTER site (http://www.projectcounter.org/compliantvendors.html).
You need to select an approach to access control and securitySecurity and access control is often a concern when implementing a web service. One of the challenges is to ensure that the security scheme you implement does not negatively impact interoperability. Start by reading Appendix G, "Security Considerations" in the SUSHI Standard.
You need to develop the SUSHI service.There are a number of tools; see note above.
For .NET developers, EBSCO has provided an open source software developer’s toolkit that provides an excellent framework for doing your work. Download the SDK from http://code.google.com/p/ebscosushisdk/ and start by reading the documentation in the zip file. You need to test the results. Serials Solutions has kindly provided an open source SUSHI client that is ideal for testing your server and validating the results. Access the client and its source code at: http://code.google.com/p/sushicounterclient/.
You need to have others help with the testing.The SUSHI developer community is a great place to ask for help. When you are ready to have others try your new service, send a note to the developer list (sign up at: http://www.niso.org/lists/sushidevelopers/) and ask for volunteers.
You need to consider options for scalability.COUNTER reports can be very big; therefore, you need to consider how best to scale your SUSHI server for peak times. Look in the SUSHI FAQs on this Web page for suggestions like preventing overloading the server by queuing up requests.
You need to release and register your server.The final step is registering your server on the SUSHI Server registry: http://sites.google.com/site/sushiserverregistry/. Select the “Join the registry” link beneath the NISO logo and add your data. It will appear in the registry within one or two days.
Getting Started: For Developers of SUSHI Client Applications
In basic terms, SUSHI (ANSI/NISO Z39.93-2013, The Standardized Usage Statistics Harvesting Protocol) provides instructions to automate the collection of usage statistics reports that librarians would otherwise manually download from a vendor website or receive via e-mail. SUSHI is a relatively simple request-response protocol that calls for a client-server implementation. Typically, the usage statistics management software used by librarians will act as a client that sends a request to a web service implemented by a publisher or content provider. If you are a developer working for a library or an organization that is developing software to harvest and/or processes usage statistics, you will be developing the client application that sends requests to a the content provider’s SUSHI web service.
You will find lots of helpful information on the SUSHI website (www.niso.org/standards-committees/sushi) that will make your job much easier -- THE MOST IMPORTANT OF WHICH IS THE LINK TO THE MISO CLIENT SOFTWARE. The MISO client is a working SUSHI client that is available through the Google Code site (http://code.google.com/p/sushicounterclient/). It includes an executable, complete configuration information and source code that can be used under the terms the New BSD License.
Another invaluable resource is the SUSHI Server Registry, which can be linked to from the NISO site or accessed directly at http://sites.google.com/site/sushiserverregistry/. This registry lists content providers offering SUSHI and provides details about what you need to do to use their SUSHI service.
Finally, remember that as you embark on this project you are not alone. The SUSHI Developer List (groups.niso.org/lists/sushidevelopers/) provides you with access to a number of experts who can answer questions and provide guidance.
Here is a quick checklist of things you need to consider when developing your client application. You will notice that there are a number of things to take into consideration before you begin developing your client.
COUNTER FAQ
1. Where do I report problems with COUNTER reports from a content provider?
In the event that you encounter a COUNTER report that does not appear to be compliant with the current COUNTER Code of Practice, COUNTER wants to know about it if direct discussions with the content provider do not resolve the situation. Report such issues to Peter Shepherd at: pshepherd@projectCounter.org and include the following information:
- A copy of the report/file in question
- The name of the content provider
- The name of the customer (including customer code if available) whose usage the report represents
- A description of the problem or concern
COUNTER will take the matter up with the content provider concerned and will also use this input to enhance future versions of the Code of Practice and to improve the audit process.
2. Does the COUNTER XML include “Total for all Journals”?
No. COUNTER XML reports are designed for machine-to-machine transfer of usage data and they are not intended for direct human viewing. The library (or other recipient) will use a software program of some kind (e.g. a usage consolidation module of an ERM) to display or otherwise process the data; therefore, the expectation is that software will total the data as necessary.
Note: inclusion of a “Totals” node in the XML adds complexity to the client-side software processing the COUNTER XML in that it needs to be programmed to recognize and ignore the “totals” node. In short, the Totals node is not used and it just makes both client and server more complicated to develop.
3. Should the COUNTER XML include report totals for each journal, database or platform when multiple months of data are requested?
No. COUNTER XML reports are designed for machine-to-machine transfer of usage data and are not intended for human viewing. For example, when multiple months of data are requested for Journal Report 1, the COUNTER XML should include usage for each month for each journal; however, it should not include totals for all months for each journal. Inclusion of totals and subtotals for the range of months is both unnecessary and undesirable. Unnecessary because the software into which the use is loaded will handle any needed summarization, undesirable because it makes the client and server software more complex.
The COUNTER Codes of Practice do not require the XML to contain all the elements of the Excel versions of the reports. The XML is intended to transfer the raw usage information. The Excel versions are intended for human viewing and thus include totals and sub-totals not necessary in the XML.
4. For Journal Reports; if usage is reported for ft_html and ft_pdf is also necessary to include ft_total?
Yes. PDF and HTML are merely two possible formats that full text may be available in at a content provider site (others include XML, Postscript, etc.) The ft_html and ft_pdf counts were added to the Journal Reports in an effort to provide some insight into the “interface effect” of a particular user interface (if the html count is high, this could be indicative of a user having to view the html before requesting the pdf.) Because these metrics were designed to be merely indicative of the influence of the user interface, they were not intended to be inclusive.
Even though in many cases the ft_total is equal to ft_html + ft_pdf this cannot be guaranteed and the software loading the COUNTER report will have no way of knowing; therefore, ft_total metric must be included in the Journal Reports to ensure reports are comparable.
5. If a SUSHI request contains a data range that spans more than one month, should the resulting COUNTER report include just the summary totals by journal?
No. The COUNTER XML should use the date range in the request to determine the months to be reported on and then provide separate metrics for each month covered in the request. For example, if a request for Journal Report 1 is for 2012-01 through 2012-06, the resulting COUTNER XML would contain six itemPerformance elements (one for each month). Note: do NOT include a seventh “summary” node with totals for all months.
6. If a SUSHI request contains a data range that does not cover a complete month or spans partial months (e.g., 2012-01-15 to 2012-02-15), what should the COUNTER report include?
Unless there has been some explicit agreement between the client and the server, the expectation of COUNTER is to delivery reports summarized by month. In the event of a request that covers part of a month, the best practice is for the COUNTER XML to return statistics for the complete month. For example, if the request was for 2012-01-15 through 2012-02-15, the COUNTER XML would include usage for all of January 2012 and February 2012. The logic is that COUNTER reports contain month-level data; therefore, the “day” part of the dates can be ignored.
7. Should the PubYr, PubYrTo and PubYrFrom attributes on the ItemPerformance element be included for all reports?
No, this optional attribute is currently only used in Journal Report 5 (to designate the year of publication of the content accessed) and should be omitted from all other reports.
8. Can a single COUNTER report include usage for multiple platforms?
While the preference for most usage consolidation software is to have a file represent titles from one platform only, the COUNTER code of practice does permit multiple platforms to be represented in a single file and the expectation is that usage consolidation software will be able to load such a file.
9. What does a content provider have to do to become COUNTER compliant?
Refer to the Stepwise Guide to COUNTER Compliance (http://www.projectcounter.org/documents/COUNTER_compliance_stepwise_guide.pdf) which is designed to take vendors, step-by-step, through the COUNTER compliance
COUNTER Release 4 FAQ
1. Should the XML version of reports BR1 and BR2 include the metrics ft_html and ft_pdf?
If you log these transactions then include the metrics in the XML version of the report.
2. Should the XML version of COUNTER reports include entries for titles, months or metrics that do not have usage?
With the exception of JR1 for publisher usage (which explicitly states that all titles should be included), it is not necessary to include entries when there is no usage. Specifically:
- exclude any
ItemPerformance/Instanceelements with zero usage; - exclude any
ItemPerformanceelements without an Instance element; - exclude any
ReportItemselement without anItemPerformanceelement
3. For the COUNTER XML version of JR5, should the report include a monthly break down of usage for the reporting period even though the Excel version only has totals?
Yes. Include details by reporting period month. When a JR5 is reporting usage for a reporting period the spans multiple months, there should be an ItemPerformance element for each Month and PubYr (or PubYrFrom and PubYrTo combination) for which there is usage.
4. For the COUNTER XML version of JR5, how are ‘Articles in press’ and articles with an ‘Unknown’ date of publication represented?
Set the PubYr attribute to “9999” for articles in press and ‘0001’ for unknown.
5. For JR5, is it acceptable to represent the “Pre-2000” content in two columns on the report “YOP Pre-2000 (Current Files)” and “YOP Pre-2000 (Back Files)”?
No. The reporting should be based on year of publication alone. The assumption is that if a publisher sells an archive or back-file, the years of publication that represents the archive would be separate. For example, if you have an archive for content 1996 and before, then you would provide columns in the Excel for 2013, 2012, .. 2000, 1997-1999, Pre-1997
6. For the COUNTER XML version of JR5, how do I represent the notion of “pre-2000” for a publication date range?
Since the publication date range is represented by the attributes PubYrFrom and PubYrTo and these attributes only accept 4 digit year values, the recommendation is to set the PubYrFrom value to the earliest publication year being include.
7. For JR5 is it OK to represent years of publication that are from the journal archive as a textual string “Archive” or “XYZ Back File”?
No, usage consolidation systems that are processing JR5 files require consistency across content providers. To that end the publication date ranges must be represented in terms of years. The only exception to this is the use of the special case ‘Articles in press’ and ‘Unknown’ in the Excel version (even these are represented as 4 digit values of ‘9999’ and ‘0001’ respectively in the XML version of the report)
8. In JR2, if a journal is not available for licensing by simultaneous user, does the publisher still need to include the ItemPerformance element representing Access denied: concurrent/simultaneous user licence limit exceeded with a count of zero?
No, only include ItemPerformance elements that have usage greater than zero. And only include titles (ReportItems element) that have usage for at least one of the metric types covered by the report.
9. For CR1 should the report include titles that have no usage at all during the reporting period?
No, only include titles (ReportItems element) that have usage for at least one of the metric types covered by the report .
10. For CR1 If a journal has no usage within a given reporting period month should an ItemPerformance element be included for that month with a usage count set to zero?
No, only include ItemPerformance elements when usage represented is greater than zero.